Video Reference
Step 1: Download Zookeeper
wget http://www.eu.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
Step 2:
tar -zxcf zookeeper-3.4.6.tar.gz
cd zookeeper-3.4.6
cd conf
Step 3:
cp zookeeper_sample.cfg zoo.cfg
vi zoo.cfg
tickTime=2000
dataDir=/home/hadoop/zookeeper
clientPort=2181
Step 4: Download Storm
wget http://apache.mesi.com.ar/storm/apache-storm-0.9.3/apache-storm-0.9.3.tar.gz
Step 5:
tar -zxvf apache-storm-0.9.3.tar.gz
cd apache-storm-0.9.3
cd conf
Step 6:
vi storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.zookeeper.port: 2181
nimbus.host: "localhost"
Step 6: Start all the service (Zookeeper + Storm )
Zookeeper
bin/zkServer.sh start
jps
QuorumPeerMain
 Storm
Storm
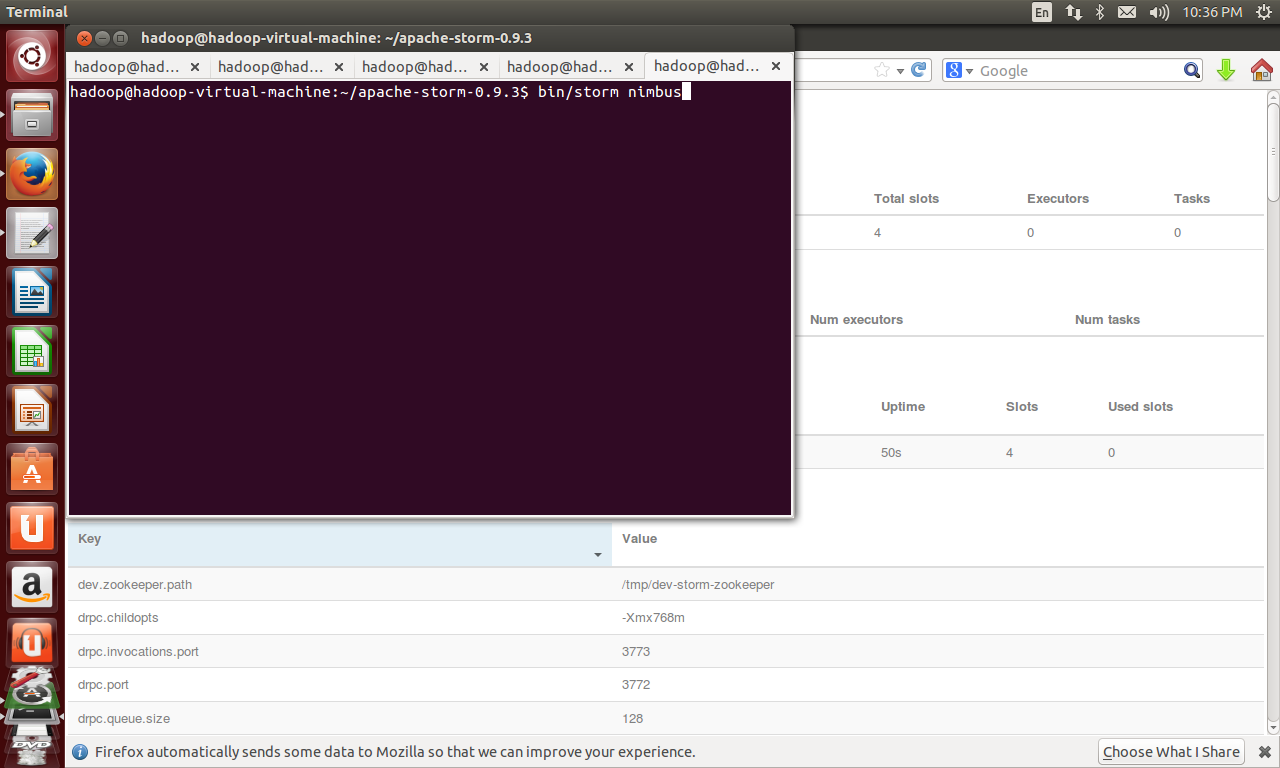
bin/storm nimbus

bin/storm supervisor

bin/storm ui

JPS over all service

Step 7:Check UI
localhost:8080

Additional Native dependencies:(Optional to install but need when you go for advance )
wget http://download.zeromq.org/zeromq-2.1.7.tar.gz
tar –xzf zeromq-2.1.7.tar.gz
cd zeromq-2.1.7
./configure
Make
sudo make install
Download and installation commands for JZMQ:
Obtain JZMQ using
git clone https://github.com/nathanmarz/jzmq.git
cd jzmq
sudo apt-get install autoconf
sudo apt-get install automake
sudo apt-get install libtool
./autogen.sh
./configure
make
sudo make install
Step 1: Download Zookeeper
wget http://www.eu.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
Step 2:
tar -zxcf zookeeper-3.4.6.tar.gz
cd zookeeper-3.4.6
cd conf
Step 3:
cp zookeeper_sample.cfg zoo.cfg
vi zoo.cfg
tickTime=2000
dataDir=/home/hadoop/zookeeper
clientPort=2181
Step 4: Download Storm
wget http://apache.mesi.com.ar/storm/apache-storm-0.9.3/apache-storm-0.9.3.tar.gz
Step 5:
tar -zxvf apache-storm-0.9.3.tar.gz
cd apache-storm-0.9.3
cd conf
Step 6:
vi storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.zookeeper.port: 2181
nimbus.host: "localhost"
Step 6: Start all the service (Zookeeper + Storm )
Zookeeper
bin/zkServer.sh start
jps
QuorumPeerMain
bin/storm nimbus
bin/storm supervisor
bin/storm ui
JPS over all service
Step 7:Check UI
localhost:8080
Additional Native dependencies:(Optional to install but need when you go for advance )
wget http://download.zeromq.org/zeromq-2.1.7.tar.gz
tar –xzf zeromq-2.1.7.tar.gz
cd zeromq-2.1.7
./configure
Make
sudo make install
Download and installation commands for JZMQ:
Obtain JZMQ using
git clone https://github.com/nathanmarz/jzmq.git
cd jzmq
sudo apt-get install autoconf
sudo apt-get install automake
sudo apt-get install libtool
./autogen.sh
./configure
make
sudo make install
















{kind=link}